特殊问题:使用pathinfo时php网站总是显示首页
WIN10 IIS10 CodeIgniter框架开发个网站,本来好好的,换电脑后不管访问哪个页面,都指向首页,折腾一下午才找到原因:不支持pathinfo。
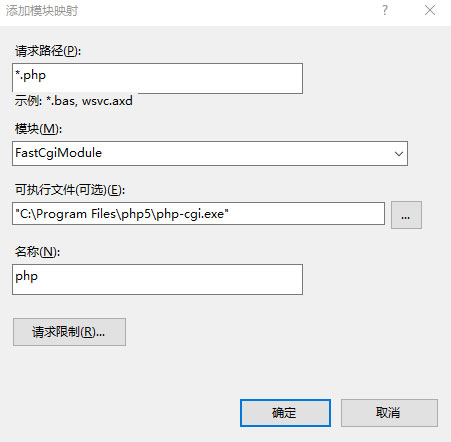
IIS“处理程序映射”中添加php支持时,要选择“添加模块映射“,而不是”添加脚本映射“。
500 内部服务器错误。 您查找的资源存在问题,因而无法显示
WIN7、WIN10 IIS 500 - 内部服务器错误解决方案
1、解决方法:打开IIS,在功能视图中找到"错误页",双击进去后,看最右边的"操作"下的"编辑功能设置...",将"错误响应"下的"详细错误"勾上。
2、网站出现问题是,浏览器去掉了"显示http友好错误提示"选项,仍然看不到具体的错误提示,而是显示,
An error occurred on the server when processing the URL. Please contact the system administrator.If you are the system administrator please click here to find out more about this error.
打开控制面板→管理工具→Internet 信息服务(IIS)管理器→双击"ASP"图标,然后在右边的窗口中展开"调试属性",把"将错误发送到浏览器"设为True即可。微软基于安全性考虑不将错误信息发送给浏览器,记得在网站正式发布时,还原此项设置。
C:/WINDOWS/TEMP 添加权限
Win10系统安装程序错误2502/2503解决方法
CI的CSRF防范原理及注意事项
首先我们谈谈什么是CSRF,它就是Cross-Site Request Forgery跨站请求伪造的简称。很多开发者甚至不够重视这个问题,认为这不是安全漏洞,而不过是恶意访问而已,它的攻击原理我在这里简单地描述一下:
有一天你打开你简单优雅逼格十足的谷歌浏览器,首先打开了一个tab页,登录并访问了你的微博首页。我们这里假设weibo.cn有这样一个网址: http://www.weibo.cn?follow_uid=123 ,意思是关注id为123的一个用户。这是一个正常的地址,访问也没有问题。
紧接着你的QQ群里发来了一个让你感到好奇的链接,http://www.comeonbaby.com, 你禁不住诱惑打开了这个链接,并在浏览器里的另一个tab页里显示出来。紧接着,你打开你的微博tab页,发现无故关注了一个新的用户。咦,这是为何?
原因很简单,很可能在你打开的http://www.comeonbaby.com链 接里存在着这样一个html元素: <img src="http://www.weibo.cn?follow_uid=123" alt="">, 浏览器试图加载这个img,很显然加载失败了,因为它不是一个有效的图片格式。但是,这个请求依然被发送出去了,此时你的微博是登录状态中,然后,你就真 的follow了123, 你看,你被强奸了。
这就是简单的csrf攻击。
在实际的网站项目中,如: http://www.abc.com/logout之类的链接都应该注意,注销类的、删除内容类的、转账类的都可能中埋伏,轻则让你感到诧异,重则数据丢失,财产损失,所以要重视任何一个对数据有操作行为的url。
那么我们在CI里如何解决呢?简单地:
第一步: 在application/config/config.php里配置以下字段:
$config['csrf_protection'] = true;
$config['csrf_token_name'] = 'csrf_token_name';
$config['csrf_cookie_name'] = 'csrf_cookie_name';
$config['csrf_expire'] = 7200;
第二步: 在form里使用form_open(),帮助生成一个token。
接下来我说一下csrf的工作原理:
简单地来说,当我们访问一个页面如: http://www.abc.com/register时, CI会生成一个名为csrf_cookie_name的cookie,其值为hash,并发送到客户端。同时由于你在该页面里使用了 form_open(),会在form标签下生成一个之类的隐藏字段,其值也为hash。
紧接着用户点击了注册按钮,浏览器将这些数据包括csrf_token_name发送到(post到)服务器,同时也会将名为 csrf_cookie_nam的cookie发送回去。服务器会比较csrf_token_name的值(也就是hash) 与 csrf_cookie_name 的cookie值(同样也是hash)是否相同, 如果相同则通过,如果不同则说明是csrf攻击。

点击查看全文:http://www.ifixedbug.com/posts/codeigniter-csrf-story
IIS10安装url重写工具2.0
http://www.microsoft.com/web/downloads/
https://www.microsoft.com/web/downloads/platform.aspx
下载并安装"web 平台安装程序",目前最新版本为5.0,双击,下一步到底即可。
打开Internet Information Services(IIS)管理器,在管理中已经多了一个"Web 平台安装程序",双击打开。
搜索"url",搜索结果第一个"URL 重写工具2.0",点击该记录后面的添加,再点击下方的安装按钮,还是一步到底,完成之后,重启下iis管理器。
iis管理器下发现多了一个"url重写"即安装成功了。接下来就是如何使用.htaccess文件了。找一个需要伪静态的项目,例如888,然后再双击"url重写"。
在IIS管理器左侧》网站,打到要支持url重写的站点,点击url重写,点击右侧导入规则,导入.htaccess文件,应用。导入.htaccess本质是在网站根目录下生成web.config文件,如果会写web.config,可不需要导入。
注:URL重写工具安装时出现需要IIS7.0以上版本,安装失败时,打开注册表编辑器,在HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\InetStp位置把MajorVersion的值改为9之后,就可以安装了,安装完成之后,再把MajorVersion的值改回10,重启一下iis。
又注:如果安装 URL重写工具2.0 还是失败,可以直接下载 rewrite_amd64.msi 安装。可百度“Download MicroSoft URL Rewrite Module 2.0",https://www.microsoft.com/en-us/download/details.aspx?id=47337
参考:
http://jingyan.baidu.com/article/b0b63dbff07fec4a48307083.html
http://zhidao.baidu.com/question/328627522371876565.html
CSS文字两端对齐
Chrome、Firefox:
text-align:justify;
IE:
text-align:justify;
text-justify:distribute; /*最后一行不两端对齐,仅IE支持text-justify*/
text-justify:distribute-all-lines; /*所有行两端对齐*/
CodeIgniter数据库操作常用函数
$this->db->select();
允许你在SQL查询中写 SELECT 部分。
$this->db->where();
$this->db->or_where();
$this->db->where_in();
允许你在SQL查询中写 WHERE部分,其余各种where语句请看手册。
$this->db->get();
运行选择查询语句并且返回结果集。可以获取一个表的全部数据。
$this->db->like();
$this->db->or_like();
$this->db->not_like();
本函数允许你生成 LIKE 子句,在做查询时非常有用,其余语法请看手册。
$this->db->order_by();
帮助你设置一个 ORDER BY 子句。
$this->db->group_by();
允许你编写查询语句中的 GROUP BY 部分:
$this->db->distinct();
为查询语句添加 "DISTINCT" 关键字:
$this->db->having();
允许你为你的查询语句编写 HAVING 部分。
$this->db->limit();
限制查询所返回的结果数量:
$this->db->select_max();
为你的查询编写一个 "SELECT MAX(field)"。
$this->db->select_min();
为你的查询编写一个 "SELECT MIN(field)" 。
$this->db->select_avg();
为你的查询编写一个 "SELECT AVG(field)" 。
$this->db->select_sum();
为你的查询编写一个 "SELECT SUM(field)" 。
$this->db->join();
允许你编写查询中的JOIN部分。
$this->db->count_all_results();
允许你获得某个特定的Active Record查询所返回的结果数量。可以使用Active Record限制函数,例如 where(), or_where(), like(), or_like() 等等。
插入数据
$this->db->insert();
生成一条基于你所提供的数据的SQL插入字符串并执行查询。你可以向函数传递 数组 或一个 对象。
$this->db->insert_batch();
一次插入多条数据,生成一条基于你所提供的数据的SQL插入字符串并执行查询。你可以向函数传递 数组 或一个 对象。
$this->db->set();
本函数使您能够设置inserts(插入)或updates(更新)值。它可以用来代替那种直接传递数组给插入和更新函数的方式。
更新数据
$this->db->update();
根据你提供的数据生成并执行一条update(更新)语句。你可以将一个数组或者对象传递给本函数。
$this->db->update_batch();
Generates an update string based on the data you supply, and runs the query. You can either pass an array or an object to the function. Here is an example using an array:
删除数据
$this->db->delete();
生成并执行一条DELETE(删除)语句。
$this->db->empty_table();
生成并执行一条DELETE(删除)语句。
$this->db->truncate();
生成并执行一条TRUNCATE(截断)语句。
链式方法
链式方法允许你以连接多个函数的方式简化你的语法。考虑一下这个范例:
$this->db->select('title')->from('mytable')->where('id', $id)->limit(10, 20);
$query = $this->db->get();
说明: 链式方法只能在PHP 5下面运行。
查询
$this->db->query();
要提交一个查询,用以下函数:
$this->db->query('YOUR QUERY HERE');
query() 函数以object(对象)的形式返回一个数据库结果集。 当使用 "read" 模式来运行查询时, 你可以使用"显示你的结果集"来显示查询结果; 当使用 "write" 模式来运行查询时, 将会仅根据执行的成功或失败来返回 TRUE 或 FALSE.
转义查询
$this->db->escape()这个函数将会确定数据类型,以便仅对字符串类型数据进行转义。并且,它也会自动把数据用单引号括起来,所以你不必手动添加单引号,用法如下: $sql = "INSERT INTO table (title) VALUES(".$this->db->escape($title).")";
查询辅助函数
$this->db->insert_id()
这个ID号是执行数据插入时的ID。
$this->db->affected_rows()
当执行写入操作(insert,update等)的查询后,显示被影响的行数。
$this->db->count_all();
计算出指定表的总行数并返回。在第一个参数中写入被提交的表名。
生成查询记录集
result()
该方法执行成功返回一个object 数组,失败则返回一个空数组。
该方法执行成功时将记录集作为关联数组返回。失败时返回空数组。
row()
该函数将当前请求的第一行数据作为 object 返回。你可以传递参数(参数是行的索引)以便获得某一行的数据。比如我们要获得第 5 行的数据: $row = $query->row(4);
row_array()
功能与 row() 一样, 区别在于该函数返回的是一个数组。
除此以外, 我们还可以使用下面的方法通过游标的方式获取记录:
$row = $query->first_row()
$row = $query->last_row()
$row = $query->next_row()
$row = $query->previous_row()
默认情况下他们将返回一个 object,同时你也可以传递参数 "array" 以便使用 array 的方式获取数据 $row = $query->first_row('array')
$row = $query->last_row('array')
$row = $query->next_row('array')
$row = $query->previous_row('array')
结果集辅助函数
$query->num_rows()
该函数将会返回当前请求的行数。
该函数返回当前请求的字段数(列数):
$query->free_result()
该函数将会释放当前查询所占用的内存并删除其关联的资源标识。
自动连接
"自动连接" 功能将在每个一页面加载时被自动实例化数据库类。要启用"自动连接",可在application/config/autoload.php中的 library 数组里添加 database:
$autoload['libraries'] = array('database');
手动连接
如果仅仅是一部分页面要求数据库连接,你可以在你有需要的函数里手工添加如下代码或者在你的类里手工添加以供该类使用。
$this->load->database();
连接多数据库
如果你需要同时连接多于一个的数据库,你可以用以下方式来实现:
$DB1 = $this->load->database('group_one', TRUE);
$DB2 = $this->load->database('group_two', TRUE);
表数据
$this->db->list_tables();
返回一个包含当前连接数据库中所有表名称的数组。
$this->db->table_exists();
有时,在对某个表执行操作之前,使用该函数判断指定表是否存在很有用。返回一个布尔值。
数据库工具类
重要提示: 初始化数据库工具类之前,你的数据库驱动必须已经运行,因为工具类依赖于此。
加载工具类: $this->load->dbutil()一旦初始化完毕,你可以通过 $this->dbutil 对象来访问成员函数:
$this->dbutil->list_databases()
$this->dbutil->database_exists();
$this->dbutil->xml_from_result($db_result)
$this->dbutil->backup()
数据库缓存类激活缓存需要三步:
1、在服务器上创建一个可写的目录以便保存缓存文件。2、在文件 application/config/database.php 中$db['xxxx']['cachedir']设置其目录。
3、激活缓存特性,可以在文件 application/config/database.php 中设置全局选项$db['xxxx']['cache_on']='TRUE',也可以用以本页下面的方法手动设置。
一旦被激活,每一次含有数据库查询的页面被加载时缓存就会自动发生。
当有数据库更新,我们需要删除缓存文件
$this->db->cache_delete()
选择数据
允许你在SQL查询中写 SELECT 部分。
$this->db->where();
$this->db->or_where();
$this->db->where_in();
允许你在SQL查询中写 WHERE部分,其余各种where语句请看手册。
$this->db->get();
运行选择查询语句并且返回结果集。可以获取一个表的全部数据。
$this->db->like();
$this->db->or_like();
$this->db->not_like();
本函数允许你生成 LIKE 子句,在做查询时非常有用,其余语法请看手册。
$this->db->order_by();
帮助你设置一个 ORDER BY 子句。
$this->db->group_by();
允许你编写查询语句中的 GROUP BY 部分:
$this->db->distinct();
为查询语句添加 "DISTINCT" 关键字:
$this->db->having();
允许你为你的查询语句编写 HAVING 部分。
$this->db->limit();
限制查询所返回的结果数量:
$this->db->select_max();
为你的查询编写一个 "SELECT MAX(field)"。
$this->db->select_min();
为你的查询编写一个 "SELECT MIN(field)" 。
$this->db->select_avg();
为你的查询编写一个 "SELECT AVG(field)" 。
$this->db->select_sum();
为你的查询编写一个 "SELECT SUM(field)" 。
$this->db->join();
允许你编写查询中的JOIN部分。
$this->db->count_all_results();
允许你获得某个特定的Active Record查询所返回的结果数量。可以使用Active Record限制函数,例如 where(), or_where(), like(), or_like() 等等。
插入数据
$this->db->insert();
生成一条基于你所提供的数据的SQL插入字符串并执行查询。你可以向函数传递 数组 或一个 对象。
$this->db->insert_batch();
一次插入多条数据,生成一条基于你所提供的数据的SQL插入字符串并执行查询。你可以向函数传递 数组 或一个 对象。
$this->db->set();
本函数使您能够设置inserts(插入)或updates(更新)值。它可以用来代替那种直接传递数组给插入和更新函数的方式。
更新数据
$this->db->update();
$this->db->update_batch();
Generates an update string based on the data you supply, and runs the query. You can either pass an array or an object to the function. Here is an example using an array:
删除数据
$this->db->delete();
生成并执行一条DELETE(删除)语句。
$this->db->empty_table();
生成并执行一条DELETE(删除)语句。
$this->db->truncate();
生成并执行一条TRUNCATE(截断)语句。
链式方法
链式方法允许你以连接多个函数的方式简化你的语法。考虑一下这个范例:
$this->db->select('title')->from('mytable')->where('id', $id)->limit(10, 20);$query = $this->db->get();
说明: 链式方法只能在PHP 5下面运行。
查询
$this->db->query();
要提交一个查询,用以下函数:$this->db->query('YOUR QUERY HERE');
query()
函数以object(对象)的形式返回一个数据库结果集。 当使用 "read" 模式来运行查询时, 你可以使用"显示你的结果集"来显示查询结果; 当使用 "write" 模式来运行查询时, 将会仅根据执行的成功或失败来返回 TRUE 或 FALSE.
转义查询
$this->db->escape()
这个函数将会确定数据类型,以便仅对字符串类型数据进行转义。并且,它也会自动把数据用单引号括起来,所以你不必手动添加单引号,用法如下: $sql = "INSERT INTO table (title) VALUES(".$this->db->escape($title).")";
查询辅助函数
$this->db->insert_id()
这个ID号是执行数据插入时的ID。
当执行写入操作(insert,update等)的查询后,显示被影响的行数。
$this->db->count_all();
计算出指定表的总行数并返回。在第一个参数中写入被提交的表名。
生成查询记录集
result()
该方法执行成功返回一个object 数组,失败则返回一个空数组。
该方法执行成功时将记录集作为关联数组返回。失败时返回空数组。
row()
该函数将当前请求的第一行数据作为 object 返回。你可以传递参数(参数是行的索引)以便获得某一行的数据。比如我们要获得第 5 行的数据: $row = $query->row(4);
row_array()
功能与 row() 一样, 区别在于该函数返回的是一个数组。
除此以外, 我们还可以使用下面的方法通过游标的方式获取记录:
$row = $query->first_row()
$row = $query->last_row()
$row = $query->next_row()
$row = $query->previous_row()
默认情况下他们将返回一个 object,同时你也可以传递参数 "array" 以便使用 array 的方式获取数据 $row = $query->first_row('array')
$row = $query->last_row('array')
$row = $query->next_row('array')
$row = $query->previous_row('array')
结果集辅助函数
$query->num_rows()
该函数将会返回当前请求的行数。$query->num_fields()
该函数返回当前请求的字段数(列数):
$query->free_result()
该函数将会释放当前查询所占用的内存并删除其关联的资源标识。
自动连接
"自动连接" 功能将在每个一页面加载时被自动实例化数据库类。要启用"自动连接",可在application/config/autoload.php中的 library 数组里添加 database:
$autoload['libraries'] = array('database');
手动连接
如果仅仅是一部分页面要求数据库连接,你可以在你有需要的函数里手工添加如下代码或者在你的类里手工添加以供该类使用。
$this->load->database();
连接多数据库
如果你需要同时连接多于一个的数据库,你可以用以下方式来实现:
$DB1 = $this->load->database('group_one', TRUE);
$DB2 = $this->load->database('group_two', TRUE);
表数据
$this->db->list_tables();
返回一个包含当前连接数据库中所有表名称的数组。
$this->db->table_exists();
有时,在对某个表执行操作之前,使用该函数判断指定表是否存在很有用。返回一个布尔值。
数据库工具类
重要提示: 初始化数据库工具类之前,你的数据库驱动必须已经运行,因为工具类依赖于此。
加载工具类: $this->load->dbutil()一旦初始化完毕,你可以通过 $this->dbutil 对象来访问成员函数:
$this->dbutil->list_databases()
$this->dbutil->database_exists();
$this->dbutil->xml_from_result($db_result)
$this->dbutil->backup()
数据库缓存类
激活缓存需要三步:
1、在服务器上创建一个可写的目录以便保存缓存文件。2、在文件 application/config/database.php 中$db['xxxx']['cachedir']设置其目录。
3、激活缓存特性,可以在文件 application/config/database.php 中设置全局选项$db['xxxx']['cache_on']='TRUE',也可以用以本页下面的方法手动设置。
一旦被激活,每一次含有数据库查询的页面被加载时缓存就会自动发生。
当有数据库更新,我们需要删除缓存文件
$this->db->cache_delete()删除缓存文件与特定网页。如果你需要清除缓存后,更新您的数据库
$this->db->cache_delete('/blog', 'comments');
注意,手册上写的是 $this->db->cache_delete('blog', 'comments');但根据实际测试应该在控制器名字前加斜杠'/'才能正确执行。
$this->db->cache_delete_all()
清除所有所有的缓存文件。
数据库维护类
注意: 欲初始化数据库维护类,请确保你的数据库驱动已经运行,因为该类依赖于数据库驱动。使用如下方法载入数据库维护类:
$this->load->dbforge()
一旦初始化,就可以使用$this->dbforge 对象访问类中函数:
$this->dbforge->create_database('db_name')
允许你创建由第一个参数指定的数据库。
$this->dbforge->drop_database('db_name')
允许你删除由第一个参数指定的数据库。
$this->dbforge->create_table('table_name');
声明了字段和键之后,你就可以创建一个表。 删除缓存文件与特定网页。如果你需要清除缓存后,更新您的数据库
$this->db->cache_delete('/blog', 'comments');
注意,手册上写的是 $this->db->cache_delete('blog', 'comments');但根据实际测试应该在控制器名字前加斜杠'/'才能正确执行。
$this->db->cache_delete_all()
清除所有所有的缓存文件。
数据库维护类
注意: 欲初始化数据库维护类,请确保你的数据库驱动已经运行,因为该类依赖于数据库驱动。使用如下方法载入数据库维护类:
$this->load->dbforge()
一旦初始化,就可以使用$this->dbforge 对象访问类中函数:
$this->dbforge->create_database('db_name')
允许你创建由第一个参数指定的数据库。
$this->dbforge->drop_database('db_name')
允许你删除由第一个参数指定的数据库。
$this->dbforge->create_table('table_name');
声明了字段和键之后,你就可以创建一个表。

